
Нейросеть будет лучше распознавать тексты архивов, если научить ее догадываться
Нейросеть будет лучше распознавать архивные тексты, если научить ее догадываться — именно таким выводом поделился Андрей Михеев, заместитель руководителя сервиса «Поиск по архивам» ООО «Яндекс», во время доклада в рамках I стратегической сессии «Информационные технологии и языки народов России», прошедшей на прошлой неделе.
В частности, в своем докладе «Разработка и внедрение технологий распознавания рукописного текста: опыт сервиса “Поиск по архивам”» спикер рассказал о достигнутых успехах и текущих вызовах при оцифровке и распознавании архивных текстов с использованием технологий оптического распознавания символов (OCR).
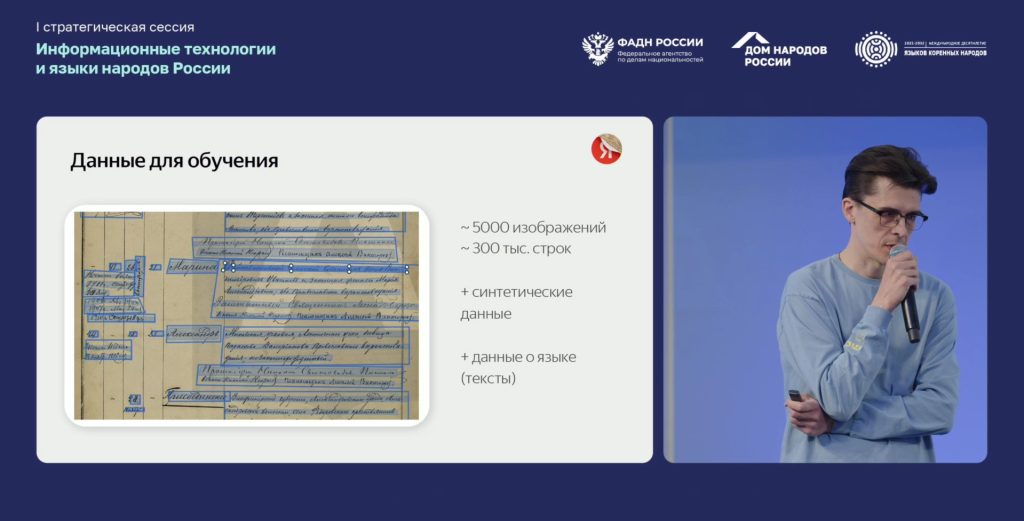
Обучение распознаванию рукописного текста представляет собой особенно сложную задачу, в отличие от обучения обработке печатного текста. Одна из основных трудностей заключается в необходимости находить и распознавать отдельные слова, группировать их в строки и объединять в смысловые блоки. Часто писари делали записи небрежно, что значительно усложняет их чтение даже для человека, не говоря уже об OCR.
Основными преградами являются множество вариантов написания букв, разный выбор расстояний между буквами и словами, использование выносных букв, дореформенная орфография и низкая степень сохранности документов. Рукописный текст уникален, и его распознавание требует учета множества факторов.

Несмотря на многочисленные вызовы, связанные с распознаванием рукописного текста в архивных документах, технология постепенно совершенствуется. По прогнозам спикера, летом модель будет значительно улучшена благодаря применению синтетических данных, что позволяет нейросети делать более точные предположения. Например, зная, что в имени «Марина» обязательно будет буква «р». Или, понимая, какие слова могли бы встречаться в тексте, а каких слов быть не могло, модель правильно «достроит» предложение. Данные о языке и его структуре существенно помогают моделям в распознавании текста.
Использование синтетических данных и обучение нейросетей догадываться о содержании текста значительно повышает точность и эффективность OCR. Эксперт отметил, что компании предстоит много работы, но успехи, достигнутые на данном этапе, говорят о перспективности разработки.
Текст: Алексей Алтынбаев
Изображения: Freepik (шапка); скриншоты трансляции стратегической сессии
Подписывайтесь на каналы Let AI be в Telegram и «ВКонтакте» — оставайтесь в курсе главных новостей в сфере искусственного интеллекта!


