
Языковые модели знают недостаточно о нашем мире
До сих пор люди не могут точно сказать, какую информацию о мире хранит в себе языковая модель и какие лингвистические знания она успела закодировать в своей матрице весов. Однако ответ на эти вопросы даст больше возможностей в области обучения моделей обработки естественного языка и интерпретации их результатов. Такую мысль высказала Елизавета Гончарова, сотрудник Института искусственного интеллекта AIRI и НИУ ВШЭ в рамках конференции AI Journey 2023.
Спикер отметила, что модели с ростом количества параметров приобретают новые способности, даже те, на которые не были специально обучены. Например, обучаясь только на одном языке, они могут легко обрабатывать и выдавать результаты на другом. Помимо этого, модель может писать программный код, не будучи специально подготовленной к этому. Также, помимо умения работать с текстом, за счет дообучения небольших слоев адаптеров (преобразующих данные из одного представления в другое) она способна ответить на вопросы по картинкам или описать аудио. Но насколько хорошо модели, обучаясь только на текстовых корпусах, могут кодировать информацию, такую как цвет и форма, специфичную для новой модальности? Кроется ли она в самой модели?
Пытаясь узнать это, команда AIRI провела ряд экспериментов с двумя моделями: одна обучена только на текстовых данных, другая — еще и на картинках. Итоги исследования показали, что векторные представления языковой модели Qwen-LM 7B были несколько неточными: фиолетовый в косинусной метрике близости с другими цветами она понимала более похожим на оранжевый, а овал в косинусном сходстве с другими фигурами оказался расположенным ближе к пятиугольнику. Тогда как мультимодальная модель Qwen Visual Language 7B представила гораздо более точные результаты. Так, фиолетовый в векторном представлении оказался ближе к красному и синему, сочетание которых и дает этот цвет, а овал рядом с прямоугольником.
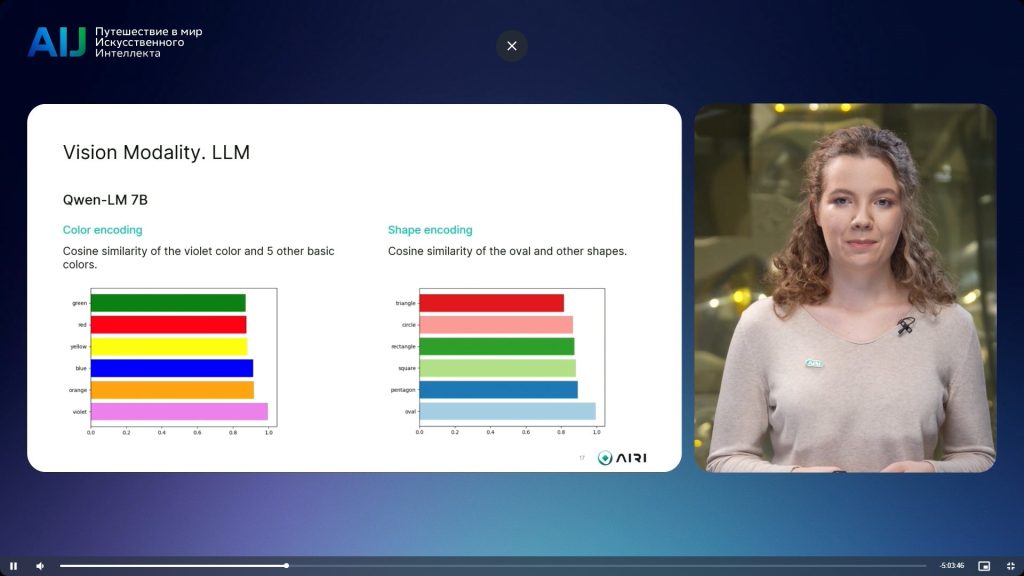
Это доказало, что модель лучше справляется с понятиями из других модальностей, если, помимо прочего, проходит дополнительное обучение с помощью других данных. Текстов недостаточно, чтобы модель получила все знания о нашем мире. По мнению спикера, добавление модальности, например визуальной, в процесс обучения языковой модели позволит открыть более сложные, более умные модели будущего.
Текст: Алексей Алтынбаев
Изображения: Freepik; AI Journey
Подписывайтесь на каналы Let AI be в Telegram и «ВКонтакте» — оставайтесь в курсе главных новостей в сфере искусственного интеллекта!


